Veröffentlicht am 5. März 2017
Der Eigenmann Rapid Engine Test ERET
Der sog. Eigenmann Rapid Engine Test (ERET) ist eine neue Sammlung von 111 Aufgaben für Schach-Programme. Er wurde konzipiert, um schnell einen ersten Eindruck von der Spielstärke einer neuen Engine ausmachen zu können. Die Computerschach-Anwenderschaft erhält mit diesem ERET erstmals eine Test-Suite an die Hand, deren Ergebnisse innert einer halben Stunde eine grobe, aber recht verlässliche Einschätzung eines (neuen) Programms erlauben.
Die 111 Stellungen bzw. ihre Hauptvarianten können nachstehend einzeln interaktiv nachgespielt und als PGN-Datei rungeladen werden. Downloadbar ist ausserdem der Test im CBH-Format (für Chessbase-Software) sowie als EPD-Datei für den Import in diverse Schach-GUI’s.
Die Vorzüge des ERET gegenüber älteren Sammlungen sind namentlich:
- grosse Bandbreite der Schachmotivik
- Eindeutigkeit der Lösungen
- Ausgewogenheit der Partiephasen
- Mittlerer bis hoher Schwierigkeitsgrad
- Schnelle Programm-Resultate
- Auch für zukünftige Engine-Generationen tauglich
Die Axiomatik des ERET-Stellungstests
Eine ambitionierte Aufgaben-Sammlung wie der ERET-Stellungstest für Schachprogramme basiert auf einer eigenen Axiomatik.
Diese lässt sich in den folgenden sechs Punkten zusammenfassen:
- Die 111 Aufgaben des ERET decken einen grossen Bereich der (computer-)schachlichen Realität ab.
- Diese abgestimmte Kompaktheit der Zusammenstellung ist weder durch Hinzufügungen noch Wegstreichungen antastbar.
- Für Computerprogramme (anders als für Menschen) ist eine Schachpartie grundsätzlich eine Sammlung von Einzel-Aufgabenstellungen unter definierten Bedingungen – ein Stellungstest also.
- Die Denk- bzw. Rechengeschwindigkeit beim Schachspielen ist eine massgebliche Komponente der „Spielstärke“.
- Das vom Test-Autor empfohlene Test-Setting ist ein integraler Bestandteil des Stellungstests.
- Unter Wahrung der Punkte 2 & 5 garantiert der ERET keine 100%ige, aber eine weitgehende Übereinstimmung seiner Testergebnisse mit den durchschnittlichen Resultaten des praktischen Engine-Turnierbetriebes.
Das Test-Setting
Das empfohlene ERET-Test-Setting sieht folgendermassen aus:

- 15 Sekunden pro Aufgabe
- Engine-Einstellungen: Default
- Prozessoren/Threads/Cores: 1-16
- Hash-Memory: 512-1024Mb
- Eröffnungsbücher: keine
- Endgame-Tablebases: beliebig
- Extra Halbzüge: 99
- Multivarianten-Modus: off
Das Design des Testes ist auf diese Einstellungen fokussiert, diese zeitigen die aussagekräftigsten Resultate. Deutlich davon abweichende Settings können die Ergebnisse verfälschen.
Die Test-Auswertung
Die Anzahl Lösungen einer Engine ergibt deren wichtigstes Testergebnis; dieses erlaubt bereits einen groben Vergleich mit anderen Programmen. Um die Resultate mehrerer Engines noch zu differenzieren, empfiehlt der Autor das Interface „Fritz“ ab Version 11, dessen Testergebnisse – aus der CBH- in eine PGN-Datei konvertiert – dann mit dem Freeware-Tool EloStatTS104 von Dr. Frank Schubert werden sollten. Diese mathematisch-statistisch fundierte Methode der Test-Auswertung ist wenn immer möglich vorzuziehen. Ausserdem ist bei einer Verwendung des Testes mit „Fritz“ die von EloStatTS104 mitgelieferte „Offset“-Test-File zu berücksichtigen: Mit ihm lassen sich die unterschiedlichen Reaktions- bzw. Initialisierungszeiten der Engines unter diesem Interface eruieren, womit nochmals genauere Ergebnisse generiert werden können (siehe hierzu die entspr. Readme-Datei).
Die „Fritz“-Alternative „Arena“
Eine Alternative zum „Fritz“-GUI ist die Freeware-Oberfläche „Arena“, die mit zusätzlichen Features beim Automatisierten Stellungstesten aufwartet und auch einen Output der Engine-Berechnungen bietet, allerdings auf jegliche Ranglisten-Generierung verzichtet bzw. nur die Anzahl Lösungen angibt, so dass keine weitergehende Differenzierung der Testergebnisse möglich ist bzw. manuell erfolgen müsste.
Andere Benutzeroberflächen bieten ebenfalls nur rudimentäre Optionen bezüglich Stellungstests und sind deshalb für den ERET nur bedingt zu empfehlen. Einen verhältnismässig differenzierten Output beim Stellungstesten liefert schliesslich noch die in Mitteleuropa kaum verbreitete GUI-Software ChessAssistant.
Die technische Durchführung des Tests ist einfach und bei den verschiedenen Schach-Interfaces wie z.B. Arena, Shredder, ChessAssistant oder Fritz grundsätzlich ähnlich.
Zufallsfaktor Multi-Prozessoren
Moderne Rechner mit Multi-Prozessoren- bzw. -Hyperthread-Techniken neigen zu Fluktuationen in ihrer Zug-Generierung. Deren Auswirkung in der Praxis wird zwar generell sehr überschätzt, aber wer auf Nummer sicher gehen will, macht pro Engine drei bis fünf Test-Durchläufe und nimmt den Durchschnitt oder die kürzeste der jeweiligen Lösungszeiten. (Hierzu mehr im Absatz Einzel-Threat vs Multi-Thread)
Um Software-übergreifende Vergleiche zu ermöglichen, sollten die Engines mit ihren Default-Parametern getestet werden. Die Verwendung von Opening-Books ist dabei irrelevant; die meisten ERET-Aufgaben sind „out of books“. Trotzdem wird grundsätzlich ein Verzicht auf Engine-Eröffnungsbücher empfohlen, um den Einfluss von ggf. hochselektiven, bis weit ins Mittelspiel hinein reichenden Book-Varianten auszuschliessen.
Relationen entscheiden, nicht absolute Zahlen
Bei der Generierung von Ranglisten mit dem ERET sollten nicht die absoluten Zahlen-Ergebnisse, sondern vielmehr die Engine-Relationen beachtet werden – so wie bei den Rankings der verschiedenen bekannten Engine-Turnieren auch. Diese können bekanntlich (je nach Turnier-Settings und Berechnungsgrundlage) überraschend unterschiedlich ausfallen – siehe die einschlägigen Engine-Ranglisten CEGT, CCRL, FCP, OHCR, SPCC, FGRL u.a.
Hier findet sich ein Vergleich von fünf häufig zitierten Ranglisten im Internet mit den ERET-Ergebnissen (Stand März 2017). Dabei zeigte sich, wie überraschend genau die Ergebnisse des ERET-Stellungstestes mit den übrigen „regulären“ Rankings übereinstimmen (natürlich von ein paar üblichen „Ausreissern“ abgesehen, die in allen Ranglisten zu finden sind).
Breite Quellen-Recherche
Die einzelnen Stellungen hat der Autor über viele Monate hinweg aus verschiedensten Quellen zusammengetragen und hauptsächlich mit den drei Programmen Deep-Shredder 11/12, Critter 1.6 und RybkaWinFinder 2.2 im Hinblick auf ihre taktische Korrektheit untersucht. Ansonsten hat er auf weiteres Einzeltesten bewusst verzichtet, um den Test möglichst objektiv und nicht „geeicht“ auf bestimmte Programme gestalten zu können. (Über entsprechende Resultat-Meldungen aus der Leser- bzw. Anwenderschaft – privat oder via „Kommentar“-Funktion – würde sich der Autor freuen).

Trotz der relativ kurzen Zeit-Vorgabe von 15 Sekunden/Stellung sind die ERET-Aufgaben keineswegs trivial. Viele der Aufgaben dürften sogar ganz besondere Knacknüsse auch für heutige Engines sein. Die umfangreichen persönlichen Analysen mithilfe der obengenannten Programme legen den Schluss nahe, dass dieser Test eher im oberen Schwierigkeitsbereich angesiedelt ist. Der Autor ist deshalb zuversichtlich, dass der ERET auch noch in fünf oder zehn Jahren nützlich sein wird…
Die internationale Computerschach-Anwenderschaft widmete sich eingehend dem ERET-Stellungstest und generierte mehrere Ranking-Listen auf je unterschiedlicher Hardware. Beispielhaft seien hier die ERET-Testergebnisse des deutschen Fernschach-Meisters Andreas Strangmüller erwähnt, der auf seiner viebeachteten Schach-Webseite FastGMs Rating Lists (FGRL) seit Jahren Engine-Resultate dokumentiert. Auch in den diversen Computerschach-Foren fand der ERET-Test grosse Resonanz. Stellvertretend hier ein paar Einzelergebnisse im CSS-Forum.
Die aktuelle ERET-Rangliste
Der Autor des Tests selber hat die 111 ERET-Aufgaben im Laufe der Jahre ebenfalls mehrmals von div. Programmen berechnen lassen.
Die nachfolgende Rangliste stammt vom Mai 2020 und enthält nicht weniger als 31 der aktuell stärksten Engines, wie sie von den einschlägigen Turnier-Statistik-Portalen wie z.B. den bekannten Computer Chess Rating Lists (CCRL) aufgeführt werden.
Dabei kam das folgende Hard- und Software-Equipment zum Einsatz:
AMD-Ryzen7-2700x • 3,7Mhz-64bit • 16Threads • 1024MB Hash • 5-men-Szyzygy-Tablebases • Fritz17-GUI
Bezüglich der Auswertung der Lösungsergebnisse fand das bereits erwähnte Tool EloStatTS104 Verwendung; dazu unten mehr.
Program Elo +/- Matches Score Av.Op. Solutions
01 Bluefish XR7FD (16Cores) : 2975 5 2885 61.3 % 2895 93/111
02 Crystal 140520 (16Cores) : 2967 5 2846 60.2 % 2895 91/111
03 Black Diamond XI (16Cores) : 2965 5 2801 59.9 % 2896 90/111
04 CorChess 6.0 (16Cores) : 2962 5 2791 59.5 % 2896 90/111
05 Stockfish 140520 (16Cores) : 2960 5 2804 59.1 % 2896 89/111
06 Eman 5.50 (16Cores) : 2956 5 2776 58.5 % 2896 88/111
07 SugaR-NN 260120 (16Cores) : 2956 5 2706 58.5 % 2896 87/111
08 Chimera 2 BF-Lc0-SF (16Cores) : 2950 5 2708 57.6 % 2896 85/111
09 Komodo 13.3 (16Cores) : 2946 5 2734 57.0 % 2897 85/111
10 Lc0 0.25.1 t60-3044 (1Core) : 2943 6 2785 56.5 % 2898 84/111
11 FatFritz 1.1 (1Core) : 2941 6 2748 56.1 % 2898 78/111
12 Houdini 6.03 (16Cores) : 2940 5 2685 56.1 % 2897 83/111
13 Booot 6.4 (16Cores) : 2919 6 2576 52.9 % 2899 74/111
14 Schooner 2.2 (16Cores) : 2910 6 2617 51.4 % 2900 76/111
15 Xiphos 0.6 (16Cores) : 2910 6 2573 51.4 % 2900 73/111
16 Ethereal 12 (16Cores) : 2904 6 2596 50.6 % 2900 75/111
17 Fritz 17 (16Cores) : 2890 6 2553 48.4 % 2901 70/111
18 Fizbo 2 (16Cores) : 2889 6 2511 48.1 % 2902 65/111
19 Laser 1.7 (16Cores) : 2885 6 2522 47.6 % 2902 69/111
20 RofChade 2.202 (16Cores) : 2885 6 2505 47.6 % 2902 67/111
21 Critter 1.6a (16Cores) : 2882 7 2653 47.0 % 2903 68/111
22 DeepShredder 13 (16Cores) : 2878 6 2512 46.4 % 2903 68/111
23 Andscacs 0.95 (16Cores) : 2872 6 2463 45.6 % 2903 65/111
24 Arasan 22.0 (16Cores) : 2853 7 2436 42.6 % 2905 59/111
25 Wasp 3.75(16Cores) : 2844 7 2467 41.3 % 2905 57/111
26 Fire 7.1 (16Cores) : 2844 7 2402 41.2 % 2905 54/111
27 DeepRybka 4.1 (16Cores) : 2842 7 2482 40.7 % 2907 53/111
28 Naum 4.6 (16Cores) : 2815 7 2451 36.9 % 2908 47/111
29 Chiron 4 (16Cores) : 2813 7 2429 36.7 % 2908 48/111
30 Deep Junior Yokohama (16Cores) : 2797 7 2391 34.5 % 2909 41/111
31 ProDeo 2.92 (1Core) : 2697 7 2240 22.4 % 2913 16/111
BF-Lc0-SF = Brainfish & LeelaChessZero & Stockfish
Lc0 & FatFritz = RTX2080-GPU
Weiterführende Links
Für jene Leser, die sich näher mit der Thematik Computerschach & Stellungstests befassen möchten, nachfolgend ein paar weiterführende Links:
„ELO-Formel für Stellungstests“
- Frank Schubert: Lösung eines alten Problems – Autor Schubert untersucht zuerst die seinerzeit gängigen Auswerteverfahren verschiedener bekannter Stellungstests und stellt dann einen mathematisch neuen, dem FIDE-Elo-Verfahren ähnlichen Ansatz zur Differenzierung von Test-Ergebnissen vor. In einem historischen Exkurs wird auch Bezug genommen auf noch vor einigen Jahren gebräuchliche Tests von Autoren wie Bednorz, Schumacher, Gurevich oder Scheidl. Zum Schluss stellt Schubert seine eigene Methode vor, „welche die Schwächen der bisherigen Formeln beseitigt und erstmalig auf einer soliden schachlichen Theorie basiert.“ Dabei zählt das Tool nicht einfach die Anzahl richtiger Lösungen ab, sondern setzt die Ergebnisse je nach Lösungsverhalten bei den einzelnen Stellungen zueinander in Bezug; es wird also nicht nur berücksichtigt, wie viele, sondern auch welche Engines welche Aufgaben gelöst haben.
Hier lässt sich EloStatTS104 downloaden.
„Was Stellungstests testen“
- Lars Bremer: Was Stellungstests testen – IT-Journalist und Programmierer Bremer repliziert darin auf den seinerzeit heftig umstrittenen CSS-WM-Test von M. Gurevich, wobei er ebenso unverhohlen wie amüsant in die Trick-Kiste greift, um seine Test-kritische These zu untermauern: Er löschte mit einem eigens dafür geschriebenen Tool in dem als Gesamtheit konzipierten Test jeweils so lange einzelne Aufgaben, bis immer wieder Top-Resultate der zufällig gewählten (ggf. schwachen) Engine resultieren, womit Bremer den zufälligen Charakter von Test-Ergebnissen „beweisen“ wollte.
Dahinter steckt allerdings ein grober Denkfehler. Denn da selbstverständlich ein umfangreicher und durchdachter Stellungstest immer kompakt gemeint ist, seine Aufgaben aufeinander abgestimmt sind und also nicht willkürlich zusammengestrichen werden dürfen, ist Bremers Artikel wissenschaftlich nicht wirklich ernst zu nehmen und deshalb ein einziger „Quatsch“ (Zitat) – aber dennoch witzig zu lesen 🙂
„Chaos-System Deep Engine“
- Lars Bremer: Chaos-System Deep Engine – Ein seriöserer und informativer Artikel des obigen Autors zur Problematik des „Zufälligen Zuges“ bei Deep-Engines. Mit seinem „Fazit“ bezüglich der Aussagekraft von Stellungstests bei MP-Rechnern ist der Schreibende zwar nicht einverstanden: Ausgedehnte Untersuchungen könnten sehr wohl dokumentieren, dass ein durchdachtes Design eines Stellungstestes diesen „MP-Effekt“ zwar nicht restlos ausschalten, aber entscheidend abfedern kann, so dass er bezüglich Ranking schliesslich auch statistisch irrelevant wird. Doch Bremer erklärt das Phänomen aus der Sicht des Programmierers äusserst anschaulich und auch für Laien nachvollziehbar. Es wird erklärt, warum sich moderne „Deep“-Programme zuweilen völlig nicht-deterministisch, ja „chaotisch“ verhalten beim Ausspielen von Zügen.
„Einzel-Threat vs Multi-Threats“
- Tord Romstad (Stockfish): Eine kurz zusammengefasste Erklärung dieses „MP-Effektes“ findet sich auch in einem Interview, das Frank Quisinsky vor Jahren mit Tord Romstad, dem verantwortlichen Stockfish-Programmierer, sowie dessen Co-Autoren geführt hat.
Zitat: „Wenn ein Schachprogramm eine Position, irgendwo tief innerhalb des Suchbaums, untersucht, macht es Gebrauch bzw. erinnert sich an frühere bereits untersuchte Positionen der gleichen Suche. Die Zugbeschneidung, Verkürzung oder Verlängerung hängen davon ab, welche Positionen vorher überprüft wurden und wie die Ergebnisse der Untersuchung dieser Positionen waren. Der Grossteil der Informationen, der für eine Entscheidung verwendet wird, liegt im Arbeitsspeicher. Der Arbeitsspeicher steht allen Prozessoren zur Verfügung.
Solange es nur einen Thread gibt, ist alles zu 100% reproduzierbar. Aber bei mehreren Threads beginnen seltsame Dinge zu geschehen, weil diese Threads nie synchron mit gleicher Geschwindigkeit aktiv sein können. Immer wieder wird eine CPU für ein paar Millisekunden eine Pause einlegen müssen und das Betriebssystem weist dann sofort eine andere Aufgabe zu. Das geschieht zufällig und ist nicht vorhersehbar, eine Kontrolle gibt es hierfür nicht. Als Konsequenz erreicht jeder Prozessor eine bestimmte Position eher zufällig und das wirkt sich dann auf die Suche nach Entscheidungen zur aktuellen Position aus.“ - Chess Programming Wiki: Hier finden sich einige „klassische“ Stellungstests (inkl. Stellungsdiagramme), die allerdings heute eher historische denn schachliche Bedeutung haben.
Der ERET-Stellungstest als EPD-/FEN-Liste
r1bqk1r1/1p1p1n2/p1n2pN1/2p1b2Q/2P1Pp2/1PN5/PB4PP/R4RK1 w q – – bm Rxf4; id „ERET 001 – Entlastung“;
r1n2N1k/2n2K1p/3pp3/5Pp1/b5R1/8/1PPP4/8 w – – bm Ng6; id „ERET 002 – Zugzwang“;
r1b1r1k1/1pqn1pbp/p2pp1p1/P7/1n1NPP1Q/2NBBR2/1PP3PP/R6K w – – bm f5; id „ERET 003 – Linienoeffnen“;
5b2/p2k1p2/P3pP1p/n2pP1p1/1p1P2P1/1P1KBN2/7P/8 w – – bm Nxg5; id „ERET 004 – Endspiel“;
r3kbnr/1b3ppp/pqn5/1pp1P3/3p4/1BN2N2/PP2QPPP/R1BR2K1 w kq – – bm Bxf7; id „ERET 005 – Laeuferopfer f7“;
r2r2k1/1p1n1pp1/4pnp1/8/PpBRqP2/1Q2B1P1/1P5P/R5K1 b – – bm Nc5; id „ERET 006 – Springeropfer“;
2rq1rk1/pb1n1ppN/4p3/1pb5/3P1Pn1/P1N5/1PQ1B1PP/R1B2RK1 b – – bm Nde5; id „ERET 007 – Laeuferpaar“;
r2qk2r/ppp1bppp/2n5/3p1b2/3P1Bn1/1QN1P3/PP3P1P/R3KBNR w KQkq – bm Qxd5; id „ERET 008 – Zentrum“;
rnb1kb1r/p4p2/1qp1pn2/1p2N2p/2p1P1p1/2N3B1/PPQ1BPPP/3RK2R w Kkq – bm Ng6; id „ERET 009 – Springeropfer“;
5rk1/pp1b4/4pqp1/2Ppb2p/1P2p3/4Q2P/P3BPP1/1R3R1K b – – bm d4; id „ERET 010 – Freibauer“;
r1b2r1k/ppp2ppp/8/4p3/2BPQ3/P3P1K1/1B3PPP/n3q1NR w – – bm dxe5, Nf3; id „ERET 011 – Rochadeangriff“;
1nkr1b1r/5p2/1q2p2p/1ppbP1p1/2pP4/2N3B1/1P1QBPPP/R4RK1 w – – bm Nxd5; id „ERET 012 – Entlastung“;
1nrq1rk1/p4pp1/bp2pn1p/3p4/2PP1B2/P1PB2N1/4QPPP/1R2R1K1 w – – bm Qd2, Bc2; id „ERET 013 – Zentrum“;
5k2/1rn2p2/3pb1p1/7p/p3PP2/PnNBK2P/3N2P1/1R6 w – – bm Nf3; id „ERET 014 – Endspiel“;
8/p2p4/r7/1k6/8/pK5Q/P7/b7 w – – bm Qd3; id „ERET 015 – Endspiel“;
1b1rr1k1/pp1q1pp1/8/NP1p1b1p/1B1Pp1n1/PQR1P1P1/4BP1P/5RK1 w – – bm Nc6; id „ERET 016 – Pos. Opfer“;
1r3rk1/6p1/p1pb1qPp/3p4/4nPR1/2N4Q/PPP4P/2K1BR2 b – – bm Rxb2; id „ERET 017 – Koenigsangriff“;
r1b1kb1r/1p1n1p2/p3pP1p/q7/3N3p/2N5/P1PQB1PP/1R3R1K b kq – bm Qg5; id „ERET 018 – Entwicklung“;
3kB3/5K2/7p/3p4/3pn3/4NN2/8/1b4B1 w – – bm Nf5; id „ERET 019 – Endspiel“;
1nrrb1k1/1qn1bppp/pp2p3/3pP3/N2P3P/1P1B1NP1/PBR1QPK1/2R5 w – – bm Bxh7; id „ERET 020 – Laeuferopfer h7“;
3rr1k1/1pq2b1p/2pp2p1/4bp2/pPPN4/4P1PP/P1QR1PB1/1R4K1 b – – bm Rc8; id „ERET 021 – Prophylaxe“;
r4rk1/p2nbpp1/2p2np1/q7/Np1PPB2/8/PPQ1N1PP/1K1R3R w – – bm h4; id „ERET 022 – Freibauer“;
r3r2k/1bq1nppp/p2b4/1pn1p2P/2p1P1QN/2P1N1P1/PPBB1P1R/2KR4 w – – bm Ng6; id „ERET 023 – Rochadeangriff“;
r2q1r1k/3bppbp/pp1p4/2pPn1Bp/P1P1P2P/2N2P2/1P1Q2P1/R3KB1R w KQ – am b3; id „ERET 024 – Entwicklung“;
2kb4/p7/r1p3p1/p1P2pBp/R2P3P/2K3P1/5P2/8 w – – bm Bxd8; id „ERET 025 – Endspiel“;
rqn2rk1/pp2b2p/2n2pp1/1N2p3/5P1N/1PP1B3/4Q1PP/R4RK1 w – – bm Nxg6; id „ERET 026 – Springeropfer“;
8/3Pk1p1/1p2P1K1/1P1Bb3/7p/7P/6P1/8 w – – bm g4; id „ERET 027 – Zugzwang“;
4rrk1/Rpp3pp/6q1/2PPn3/4p3/2N5/1P2QPPP/5RK1 w – – am Rxb7; id „ERET 028 – Vergifteter Bauer“;
2q2rk1/2p2pb1/PpP1p1pp/2n5/5B1P/3Q2P1/4PPN1/2R3K1 w – – bm Rxc5; id „ERET 029 – Qualitaetsopfer“;
rnbq1r1k/4p1bP/p3p3/1pn5/8/2Np1N2/PPQ2PP1/R1B1KB1R w KQ – bm Nh4; id „ERET 030 – Initiative“;
4b1k1/1p3p2/4pPp1/p2pP1P1/P2P4/1P1B4/8/2K5 w – – bm b4; id „ERET 031 – Endspiel“;
8/7p/5P1k/1p5P/5p2/2p1p3/P1P1P1P1/1K3Nb1 w – – bm Ng3; id „ERET 032 – Zugzwang“;
r3kb1r/ppnq2pp/2n5/4pp2/1P1PN3/P4N2/4QPPP/R1B1K2R w KQkq – bm Nxe5; id „ERET 033 – Initiative“;
b4r1k/6bp/3q1ppN/1p2p3/3nP1Q1/3BB2P/1P3PP1/2R3K1 w – – bm Rc8; id „ERET 034 – Laeuferpaar“;
r3k2r/5ppp/3pbb2/qp1Np3/2BnP3/N7/PP1Q1PPP/R3K2R w KQkq – bm Nxb5; id „ERET 035 – Qualitaetsopfer“;
r1k1n2n/8/pP6/5R2/8/1b1B4/4N3/1K5N w – – bm b7; id „ERET 036 – Endspiel“;
1k6/bPN2pp1/Pp2p3/p1p5/2pn4/3P4/PPR5/1K6 w – – bm Na8; id „ERET 037 – Zugzwang“;
8/6N1/3kNKp1/3p4/4P3/p7/P6b/8 w – – bm exd5; id „ERET 038 – Endspiel“;
r1b1k2r/pp3ppp/1qn1p3/2bn4/8/6P1/PPN1PPBP/RNBQ1RK1 w kq – bm a3; id „ERET 039 – Entwicklung“;
r3kb1r/3n1ppp/p3p3/1p1pP2P/P3PBP1/4P3/1q2B3/R2Q1K1R b kq – bm Bc5; id „ERET 040 – Koenigssicherheit“;
3q1rk1/2nbppb1/pr1p1n1p/2pP1Pp1/2P1P2Q/2N2N2/1P2B1PP/R1B2RK1 w – – bm Nxg5; – id „ERET 041 – Springeropfer“;
8/2k5/N3p1p1/2KpP1P1/b2P4/8/8/8 b – – bm Kb7; id „ERET 042 – Endspiel“;
2r1rbk1/1pqb1p1p/p2p1np1/P4p2/3NP1P1/2NP1R1Q/1P5P/R5BK w – – bm Nxf5; id „ERET 043 – Springeropfer“;
rnb2rk1/pp2q2p/3p4/2pP2p1/2P1Pp2/2N5/PP1QBRPP/R5K1 w – – bm h4; id „ERET 044 – Linienoeffnen“;
5rk1/p1p1rpb1/q1Pp2p1/3Pp2p/4Pn2/1R4N1/P1BQ1PPP/R5K1 w – – bm Rb4; id „ERET 045 – Initiative“;
8/4nk2/1p3p2/1r1p2pp/1P1R1N1P/6P1/3KPP2/8 w – – bm Nd3; id „ERET 046 – Endspiel“;
4kbr1/1b1nqp2/2p1p3/2N4p/1p1PP1pP/1PpQ2B1/4BPP1/r4RK1 w – – bm Nxb7; id „ERET 047 – Entlastung“;
r1b2rk1/p2nqppp/1ppbpn2/3p4/2P5/1PN1PN2/PBQPBPPP/R4RK1 w – – bm cxd5; id „ERET 048 – Starke Felder“;
r1b1kq1r/1p1n2bp/p2p2p1/3PppB1/Q1P1N3/8/PP2BPPP/R4RK1 w kq – bm f4; id „ERET 049 – Entwicklung“;
r4r1k/p1p3bp/2pp2p1/4nb2/N1P4q/1P5P/PBNQ1PP1/R4RK1 b – – bm Nf3; id „ERET 050 – Koenigsangriff“;
6k1/pb1r1qbp/3p1p2/2p2p2/2P1rN2/1P1R3P/PB3QP1/3R2K1 b – – bm Bh6; id „ERET 051 – Verteidigung“;
2r2r2/1p1qbkpp/p2ppn2/P1n1p3/4P3/2N1BB2/QPP2PPP/R4RK1 w – – bm b4; id „ERET 052 – Starke Felder“;
r1bq1rk1/p4ppp/3p2n1/1PpPp2n/4P2P/P1PB1PP1/2Q1N3/R1B1K2R b KQ – bm c4; id „ERET 053 – Pos. Opfer“;
2b1r3/5pkp/6p1/4P3/QppqPP2/5RPP/6BK/8 b – – bm c3; id „ERET 054 – Endspiel“;
r2q1rk1/1p2bpp1/p1b2n1p/8/5B2/2NB4/PP1Q1PPP/3R1RK1 w – – bm Bxh6; id „ERET 055 – Laeuferopfer h6“;
r2qr1k1/pp2bpp1/2pp3p/4nbN1/2P4P/4BP2/PPPQ2P1/1K1R1B1R w – – bm Be2; id „ERET 056 – Zwischenzug“;
r2qr1k1/pp1bbp2/n5p1/2pPp2p/8/P2PP1PP/1P2N1BK/R1BQ1R2 w – – bm d6; id „ERET 057 – Abtausch“;
8/8/R7/1b4k1/5p2/1B3r2/7P/7K w – – bm h4; id „ERET 058 – Endspiel“;
rq6/5k2/p3pP1p/3p2p1/6PP/1PB1Q3/2P5/1K6 w – – bm Qd3; id „ERET 059 – Endspiel“;
q2B2k1/pb4bp/4p1p1/2p1N3/2PnpP2/PP3B2/6PP/2RQ2K1 b – – bm Qxd8; id „ERET 060 – Koenigsangriff“;
4rrk1/pp4pp/3p4/3P3b/2PpPp1q/1Q5P/PB4B1/R4RK1 b – – bm Rf6; id „ERET 061 – Koenigsangriff“;
rr1nb1k1/2q1b1pp/pn1p1p2/1p1PpNPP/4P3/1PP1BN2/2B2P2/R2QR1K1 w – – bm g6; id „ERET 062 – Starke Felder“;
r3k2r/4qn2/p1p1b2p/6pB/P1p5/2P5/5PPP/RQ2R1K1 b kq – bm Kf8; id „ERET 063 – Verteidigung“;
8/1pp5/p3k1pp/8/P1p2PPP/2P2K2/1P3R2/5r2 b – – am Rxf2; id „ERET 064 – Endspiel“;
1r3rk1/2qbppbp/3p1np1/nP1P2B1/2p2P2/2N1P2P/1P1NB1P1/R2Q1RK1 b – – bm Qb6; id „ERET 065 – Zwischenzug“;
8/2pN1k2/p4p1p/Pn1R4/3b4/6Pp/1P3K1P/8 w – – bm Ke1; id „ERET 066 – Endspiel“;
5r1k/1p4bp/3p1q2/1NpP1b2/1pP2p2/1Q5P/1P1KBP2/r2RN2R b – – bm f3; id „ERET 067 – Raeumung“;
r3kb1r/pbq2ppp/1pn1p3/2p1P3/1nP5/1P3NP1/PB1N1PBP/R2Q1RK1 w kq – bm a3; id „ERET 068 – Offene Linie“;
5rk1/n2qbpp1/pp2p1p1/3pP1P1/PP1P3P/2rNPN2/R7/1Q3RK1 w – – bm h5; id „ERET 069 – Koenigsangriff“;
r5k1/1bqp1rpp/p1n1p3/1p4p1/1b2PP2/2NBB1P1/PPPQ4/2KR3R w – – bm a3; id „ERET 070 – Starke Felder“;
1r4k1/1nq3pp/pp1pp1r1/8/PPP2P2/6P1/5N1P/2RQR1K1 w – – bm f5; id „ERET 071 – Ablenkung“;
q5k1/p2p2bp/1p1p2r1/2p1np2/6p1/1PP2PP1/P2PQ1KP/4R1NR b – – bm Qd5; id „ERET 072 – Zentralisierung“;
r4rk1/ppp2ppp/1nnb4/8/1P1P3q/PBN1B2P/4bPP1/R2QR1K1 w – – bm Qxe2; id „ERET 073 – Mobilitaet“;
1r3k2/2N2pp1/1pR2n1p/4p3/8/1P1K1P2/P5PP/8 w – – bm Kc4; id „ERET 074 – Endspiel“;
6r1/6r1/2p1k1pp/p1pbP2q/Pp1p1PpP/1P1P2NR/1KPQ3R/8 b – – bm Qf5; id „ERET 075 – Festung“;
r1b1kb1r/1p1npppp/p2p1n2/6B1/3NPP2/q1N5/P1PQ2PP/1R2KB1R w Kkq – bm Bxf6; id „ERET 076 – Entwicklung“;
r3r1k1/1bq2ppp/p1p2n2/3ppPP1/4P3/1PbB4/PBP1Q2P/R4R1K w – – bm gxf6; id „ERET 077 – Rochadeangriff“;
r4rk1/ppq3pp/2p1Pn2/4p1Q1/8/2N5/PP4PP/2KR1R2 w – – bm Rxf6; id „ERET 078 – Freibauer“;
r1bqr1k1/3n1ppp/p2p1b2/3N1PP1/1p1B1P2/1P6/1PP1Q2P/2KR2R1 w – – bm Qxe8; id „ERET 079 – Damenopfer“;
5rk1/1ppbq1pp/3p3r/pP1PppbB/2P5/P1BP4/5PPP/3QRRK1 b – – bm Bc1; id „ERET 080 – Raeumung“;
r3r1kb/p2bp2p/1q1p1npB/5NQ1/2p1P1P1/2N2P2/PPP5/2KR3R w – – bm Bg7; id „ERET 081 – Koenigsangriff“;
8/3P4/1p3b1p/p7/P7/1P3NPP/4p1K1/3k4 w – – bm g4; id „ERET 082 – Endspiel“;
3q1rk1/7p/rp1n4/p1pPbp2/P1P2pb1/1QN4P/1B2B1P1/1R3RK1 w – – bm Nb5; id „ERET 083 – Abtausch“;
4r1k1/1r1np3/1pqp1ppB/p7/2b1P1PQ/2P2P2/P3B2R/3R2K1 w – – bm Bg7; id „ERET 084 – Koenigsangriff“;
r4rk1/q4bb1/p1R4p/3pN1p1/8/2N3P1/P4PP1/3QR1K1 w – – bm Ng4; id „ERET 085 – Abtausch“;
r3k2r/pp2pp1p/8/q2Pb3/2P5/4p3/B1Q2PPP/2R2RK1 w kq – bm c5; id „ERET 086 – Qualitaetsopfer“;
r3r1k1/1bnq1pbn/p2p2p1/1p1P3p/2p1PP1B/P1N2B1P/1PQN2P1/3RR1K1 w – – bm e5; id „ERET 087 – Raeumung“;
8/4k3/p2p2p1/P1pPn2p/1pP1P2P/1P1NK1P1/8/8 w – – bm g4; id „ERET 088 – Endspiel“;
8/2P1P3/b1B2p2/1pPRp3/2k3P1/P4pK1/nP3p1p/N7 w – – bm e8N; id „ERET 089 – Unterverwandlung“;
4K1k1/8/1p5p/1Pp3b1/8/1P3P2/P1B2P2/8 w – – bm f4; id „ERET 090 – Endspiel“;
8/6p1/3k4/3p1p1p/p2K1P1P/4P1P1/P7/8 b – – bm g6, Kc6; id „ERET 091 – Endspiel“;
r1b2rk1/ppp3p1/4p2p/4Qpq1/3P4/2PB4/PPK2PPP/R6R b – – am Qxg2; id „ERET 092 – Vergifteter Bauer“;
2b1r3/r2ppN2/8/1p1p1k2/pP1P4/2P3R1/PP3PP1/2K5 w – – bm Nd6; id „ERET 093 – Endspiel“;
2k2Br1/p6b/Pq1r4/1p2p1b1/1Ppp2p1/Q1P3N1/5RPP/R3N1K1 b – – bm Rf6; id „ERET 094 – Damenopfer“;
r2qk2r/ppp1b1pp/2n1p3/3pP1n1/3P2b1/2PB1NN1/PP4PP/R1BQK2R w KQkq – bm Nxg5; id „ERET 095 – Damenopfer“;
8/8/4p1Pk/1rp1K1p1/4P1P1/1nP2Q2/p2b1P2/8 w – – bm Kf6; id „ERET 096 – Endspiel“;
2k5/p7/Pp1p1b2/1P1P1p2/2P2P1p/3K3P/5B2/8 w – – bm c5; id „ERET 097 – Endspiel“;
8/6pp/5k2/1p1r4/4R3/7P/5PP1/5K2 w – – am Ke2; id „ERET 098 – Endspiel“;
3q1r1k/4RPp1/p6p/2pn4/2P5/1P6/P3Q2P/6K1 w – – bm Re8; id „ERET 099 – Endspiel“;
rn2k2r/3pbppp/p3p3/8/Nq1Nn3/4B1P1/PP3P1P/R2Q1RK1 w k – bm Nf5; id „ERET 100 – Initiative“;
r1b1kb1N/pppnq1pB/8/3p4/3P4/8/PPPK1nPP/RNB1R3 b q – bm Ne5; id „ERET 101 – Entwicklung“;
N4rk1/pp1b1ppp/n3p1n1/3pP1Q1/1P1N4/8/1PP2PPP/q1B1KB1R b K – bm Nxb4; id „ERET 102 – Koenigsangriff“;
4k1br/1K1p1n1r/2p2pN1/P2p1N2/2P3pP/5B2/P2P4/8 w – – bm Kc8; id „ERET 103 – Zugzwang“;
r1bqkb1r/ppp3pp/2np4/3N1p2/3pnB2/5N2/PPP1QPPP/2KR1B1R b kq – bm Ne7; id „ERET 104 – Entwicklung“;
r3kb1r/pbqp1pp1/1pn1pn1p/8/3PP3/2PB1N2/3N1PPP/R1BQR1K1 w kq – bm e5; id „ERET 105 – Starke Felder“;
r2r2k1/pq2bppp/1np1bN2/1p2B1P1/5Q2/P4P2/1PP4P/2KR1B1R b – – bm Bxf6; id „ERET 106 – Koenigssicherheit“;
1r1r2k1/2pq3p/4p3/2Q1Pp2/1PNn1R2/P5P1/5P1P/4R2K b – – bm Rb5; id „ERET 107 – Verteidigung“;
8/5p1p/3P1k2/p1P2n2/3rp3/1B6/P4R2/6K1 w – – bm Ba4; id „ERET 108 – Endspiel“;
2rbrnk1/1b3p2/p2pp3/1p4PQ/1PqBPP2/P1NR4/2P4P/5RK1 b – – bm Qxd4; id „ERET 109 – Entlastung“;
4r1k1/1bq2r1p/p2p1np1/3Pppb1/P1P5/1N3P2/1R2B1PP/1Q1R2BK w – – bm c5; id „ERET 110 – Freibauer“;
8/8/8/8/4kp2/1R6/P2q1PPK/8 w – – bm a3; id „ERET 111 – Festung“;
Das Glarean Magazin auf Instagram


Wenn Sie die Arbeit des GLAREAN MAGAZINS unterstützen möchten, können Sie dies hier tun:
👉 Unterstützung via PayPal (Walter Eigenmann)
Vielen Dank.
Diesen Beitrag teilen:

{kind=link}
{kind=link}
Inhaltsverzeichnis
Entdecke mehr von Glarean Magazin
Melde dich für ein Abonnement an, um die neuesten Beiträge per E-Mail zu erhalten.
Is the position 103 broken?
4k1br/1K1p1n1r/2p2pN1/P2p1N2/2P3pP/5B2/P2P4/8 w – – 0 1
Move Kc8 seems to lose in Mate in 13
Nope, White wins, it’s a Mate in 14 :
[Event „VanEssen 2004“]
[Site „?“]
[Date „????.??.??“]
[Round „?“]
[White „ERET 103“]
[Black „Zugzwang“]
[Result „1-0“]
[SetUp „1“]
[FEN „4k1br/1K1p1n1r/2p2pN1/P2p1N2/2P3pP/5B2/P2P4/8 w – – 0 1“]
[PlyCount „27“]
[SourceTitle „ERET Engine Test“]
[Source „W. Eigenmann“]
[SourceDate „2017.03.01“]
[SourceVersion „1“]
[SourceVersionDate „2017.03.01“]
[SourceQuality „1“]
Very nice. I did not see your line, neither did my newest SF dev version.
ERET-Test Pos.93?
Es geht um die Pos.93/111
ERET 093 – Endspiel T&S&B vs T&T&L, Simkhovich 1923
Detlef Uter von https://forum.computerschach.de schreibt:
„Von Detlef Uter Datum 2021-12-09 15:09“
„93. ERET 093 – Endspiel T&S&B vs T&T&L, Simkhovich 1923 Gelöst in 0.09s/10; Gelöst: 85“
Das kann nicht sein!!
Das ist eine Position die bisher keine engine gelöst hat, siehe auch:
„Von Reinhold Stibi Datum 2021-12-09 02:39 Editiert 2021-12-09 02:44“
„93. ERET 093 – Endspiel T&S&B vs T&T&L, Simkhovich 1923 > 60s.“
Detlef Uter macht irgend etwas falsch.
Ja, Detlef Uter hat in seinen Tests eine korrupte ERET-Test-Datei benützt: https://forum.computerschach.de/cgi-bin/mwf/topic_show.pl?pid=150133#pid150133
Eventuell war auch ein ungelöschtes Memory-File bzw. Hash-File aus einer vorangegangenen Analyse oder einem früheren Testlauf im Spiel.
Beste Grüsse: W.E.
hi,
eine interesannte Position: „6r1/p1p1p1pP/P1PpP1P1/8/2P1B3/2K3pp/3P2rq/R5bk w – – „.
Es ist eine 3x fache umwandlung eines Bauern in einem Springer. Vielleicht kann man diese FEN in deinen Tests aufnehmen?
grüsse
Danke für den Hinweis – aber diese Stellung von Jan Timman ist bereits mehrfach anderweitig verwendet/diskutiert worden, z.B. hier:
http://talkchess.com/forum3/viewtopic.php?t=73982
Hallo Walter,
besten Dank für deine sehr lehrreichten Ausführungen auf meinen Feedback. Es ist tatsächlich so, dass ich mich in den vergangenen Jahren nicht mit den allerneuesten Engines befasst habe und daher meine Argumente wohl keine 5 Rappen mehr Wert sind 🙂
Im Augenblick habe ich die besten Engines (darunter Lc0, SugaR-NN mit Persistent Learning, Houdini 5.1 (6.0 ist noch besser, aber kostet was…) und die lösen tatsächlich deine Aufgaben binnen Sekunden – und verstehen sehr wohl die Lösungen aufgrund ither Varianten, im Gegensatz zu was ich vorher behauptete, Es ist schon eine andere Welt im Vergleich zu den Jahren 2000-2008, den Zeitraum den ich zuletzt gut kannte, was Engines betrifft.
Möglicherweise ist Position 90, die sehr hübsche Studie, die du auch hier auf deiner Webpage zeigst, nicht eindeutig, und lässt auch die Lösung 1.Ld1 – Ld2 2.f4!! zu, meine Programme zeigen nach manueller Analyse einen Vorteil von +3.xx, nachdem sie vergeblich an 1.Ke7 herumgerechnet haben und ich die dazugehörigen Varianten manuell eingegeben habe. Geh‘ ich zur Anfangstellung zurück rechnen sie dann an 1.Ld1 und 2.f4, und nach Eingabe dieser Varianten finden sie schliesslich auch die Lösung 1.f4!!, ein reiner Hashtable-Effekt denke ich mal.. Allerdings könnte ich mich irren, was 1.Ld1 bettrift, ich muss weiter analysieren.
Beste Grüsse,
Michael
Ja, die ERET-90-Aufgabe wurde gleich nach Erscheinen des ERET-Stellungstests diskutiert im Netz:
https://forum.computerschach.de/cgi-bin/mwf/topic_show.pl?pid=106936;hl=4K1k1%2f8%2f1p5p%2f1Pp3b1%2f8%2f1P3P2%2fP1B2P2%2f8
Es ist eine extrem komplizierte Matt-Studie zum Thema Ungleichfarbige Läufer mit zahlreichen Zugzwängen bzw. Zugumstellungen.
Momentaner Stand der Dinge scheint, dass 1.f4 schneller ist als 1.Ld1 (dass aber Ld1 praktisch gleichwertig ist).
Heute, drei Jahre später, nähme ich die Aufgabe wahrscheinlich nicht mehr in die Suite.
Oder vielleicht doch wieder? Denn Programme haben den jeweils besten Zug einer Stellung zu finden –
und das Bessere ist der Feind des Guten 🙂
W.E.
Hallo Walter,
deine zusammengestellte Schachprobleme sind sehr schön und Hilfreich – für Menschen zwecks Verbesserung ihrer Schachkenntinsse. Stellungstest allesamt, inlkusive deiner dienen meiner Meinung nach keinesfalls zur Spielstärkebestimmung eines Programms (Engine), sondern sagt lediglich aus, wie gut ein Programm zur Analyse geeignet ist. Spielstärke wird durch Spielen von Partien zwischen Gegnern bestimmt, wo auch eine Elo-Eichung ausgerechnet werden kann. Tests können – und sollten – keinesfalls auf eine Elo-Zahl schliessen. Stellungen lösen und Partien spielen sind 2 Paar Stiefel.
Dann gibt est ein weiteres gravierendes Problem mit verkürzten Testzeiten (in deinem Fall: 15 Sekunden). In einer nur kurzen Bedenkzeit können Programme den richtitgen Zug aus völlig falschem Grund ausgeben, dann diesen Zug schnell wieder verwerfen, um sich später doch wieder für dien Zug zu entscheiden. Das liegt an der besonderen Arbetisweise der Engines, für das Finden einer Gewinnbringenden Fortsetzung müssen u.U erst einmal völlig triviale Varianten durchgerechnet werden, die Zeigen, dass eine solche Fortsetzung nicht zum Gewinn fürhrt, das kostet Zeit. Ein Mensch würde nie und nimmer so vorgehen (er erkennt Muster statt Varianten). Das bedeutet, dass die Ausgabe des richtigen Zuges nach 15 Sekunden keinesfalls den eindeutigen Schluss zulässt, das Progamm hätte die Stellung auch richtig verstanden. Eine Abhife dazu könnte sein, ein Programm 2 Minuten (oder länger) rechnen zu lassen, um dann sämtliche Lösungen zu berücksichtigen, die innerhalb von 15 Sekunden gefunden wurden und für 2 Minuten die Lösung dann auch beibehält,
Es bereitet mir grosse Freude deine Stellungen zusammen mit den Engines zu analysieren! Besten Dank für deine Arbeit.
Hi Michael
Für deine Beschäftigung mit dem ERET-Computertest vielen Dank.
Dein Argumentarium enthält allerdings ein paar altbekannte Irrtümer und Missverständnisse, die gegenüber Stellungstests immer wieder geäussert werden, und die ich gerne auch hier richtigstelle.
„Stellungstests allesamt, inklusive deines dienen meiner Meinung nach keinesfalls zur Spielstärkebestimmung eines Programms (Engine), sondern sagt lediglich aus, wie gut ein Programm zur Analyse geeignet ist“.
Nein. Mit „Analyse“ im eigentlichen Sinne haben Stellungstests nichts zu tun.
Hingegen ist ein umfangreicher und sorgfältig konzipierter Stellungstest – über den ERET insbesondere und seine Axiomatik steht ja alles Notwendige im Artikel – durchaus in der Lage, als Indikator für die Spielstärke einer Engine zu fungieren.
Selbstverständlich wird er die Ranglisten, wie sie von statistisch orientierten Pools wie z.B. CCRL generiert werden, nicht 100%-ig abbilden können, und diesbezüglich Engine-„Ausreisser“ gibt es im ERET sicher (übrigens aber auch in den CCRL- oder CEGT-Pools, die eine und dieselbe Engine deutlich verschieden rangieren können…)
Es ist kein Zufall, dass die vom ERET-Stellungstest generierten Rankings verblüffend gut korrespondieren mit anderen bekannten Ranglisten. Vor drei Jahren wurde mal die damalige ERET-Rangliste verglichen mit weiteren geläufigen Rankings, und die hohe Übereinstimmung dieser sechs Listen bestätigt die Zielsetzung des ERET, nämlich innerhalb kürzester Zeit einen ersten Eindruck von der Turnier-Performance eines Programmes zu erhalten:
Der ERET im Vergleich mit anderen Rankings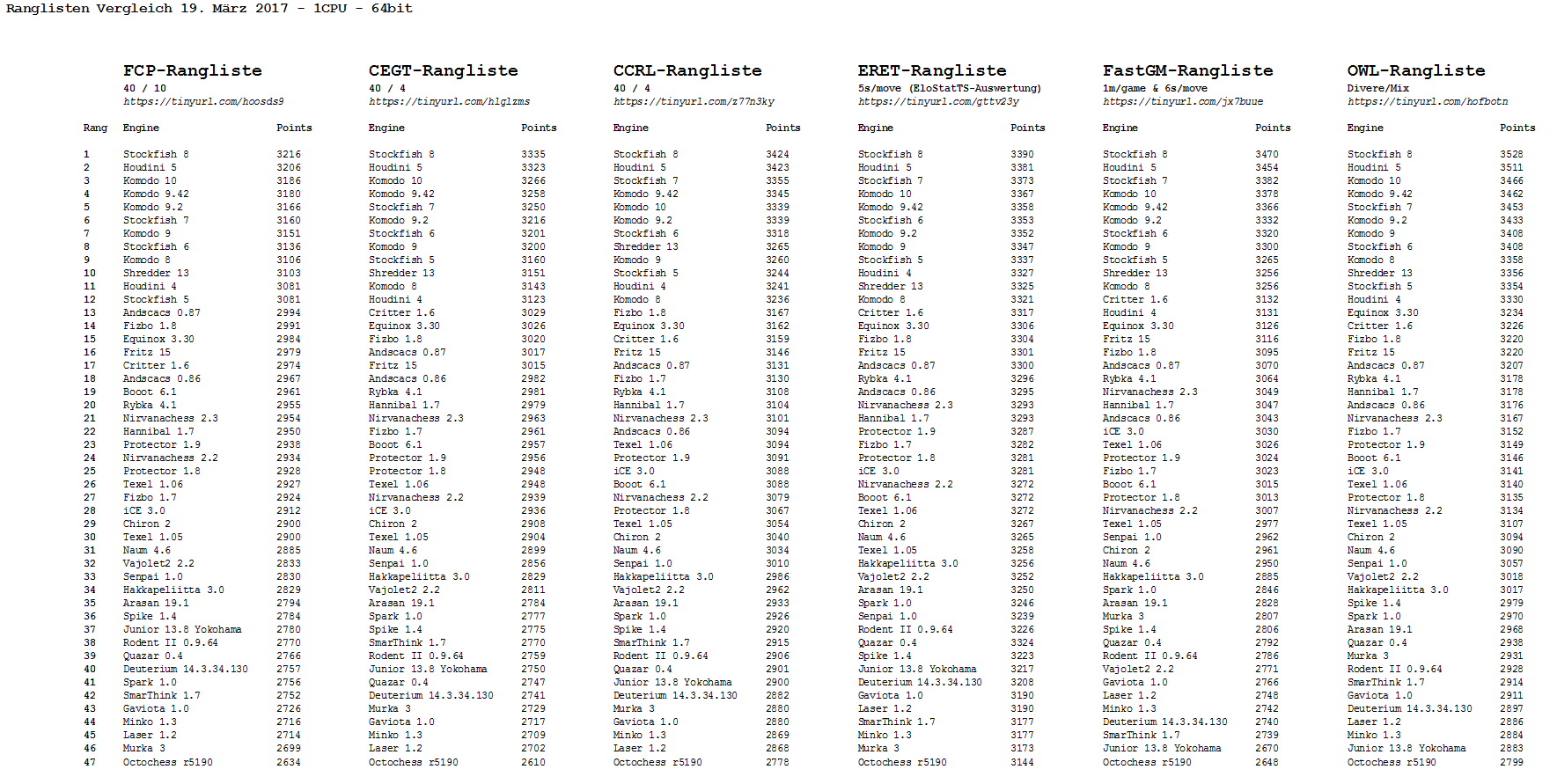
„Stellungen lösen und Partien spielen sind 2 Paar Stiefel“.
Jein.
Selbstverständlich können in einen Stellungstest Turnier-relevante Parameter wie z.B. Eröffnungstheorie oder Hash-Memorierung nur bedingt einfliessen.
Aber grundsätzlich ist für ein Schachprogramm das Spielen von (z.B. hundert) Schachpartien nichts anderes als ein gigantischer Stellungstest; Zug um Zug wird generiert, evaluiert, bewertet, ausgespielt – ein Stellungstest eben. (Es sei denn, man attestiert den Engines beim Schachspielen menschliche Qualitäten wie z.B. „planvolle Strategie“, aber zu solcher Hybris versteigen sich nicht mal die eingefleischtesten Programmierer der modernen Neuronalen Netzwerke…)
„Dann gibt est ein weiteres gravierendes Problem mit verkürzten Testzeiten (in deinem Fall: 15 Sekunden). In einer nur kurzen Bedenkzeit können Programme den richtitgen Zug aus völlig falschem Grund ausgeben, dann diesen Zug schnell wieder verwerfen, um sich später doch wieder für den Zug zu entscheiden“.
Nein. 15 Sekunden pro Zug ist heutzutage keineswegs eine kurze, sondern eine überdurchschnittlich lange Bedenkzeit.
Moderne Engines berechnen in Sekundenbruchteilen -zig hunderttausende von Stellungen. Und zwar hochselektiv und mit raffiniertesten Cut-Algorithmen. Die uralten Zeiten von Brute-Force-Techniken, wo (fast) jedem Quatsch-Zug nachgegangen wurde, sind auch bei den traditionellen Alpha-Beta-Programmen längst passé, von den aktuellen NN-Programmen ganz zu schweigen.
Der weitaus grösste Teil der heutigen Engine-Turniere spielt sich mit Bullet- oder Blitz-Bedenkzeiten ab, also zwischen 3 bis 5 Minuten pro Engine/Partie.
Bei einer durchschnittlichen Züge-Anzahl von 50-60 bei Engine-Partien sind also die 15 Sekunden des ERET pro Zug eine überdurchschnittlich lange Zeit…
Ausserdem ist eine besondere Qualität des ERET, dass er fast ausschliesslich nach solchen Lösungszügen fragt, die von einer Engine nicht mehr verworfen werden (können), sobald sie mal gefunden wurden. Dies kann, wer will, mit den Engines gerne experimentell nachprüfen.
„Es bereitet mir grosse Freude deine Stellungen zusammen mit den Engines zu analysieren! Besten Dank für deine Arbeit“.
Es freut mich, dass der ERET auch fast vier Jahre nach seiner Entstehung immer noch für Interesse sorgt in der Computerschach-Welt.
Allerdings bereitet mir Sorge, dass mittlerweile von den allerstärksten Engines durchschnittlich fast 100 der 111 Stellungen in den geforderten je 15 Sekunden gelöst werden. ;-(
Vielleicht mache ich mir allmählich Gedanken über einen ERET-2 🙂
Gruss: Walter
Naja, bin eigentlich ein Gegner von Stellungstests, wenn es um Ranglisten von Programmen geht. Erinnere mich noch an den Bratko-Kopec-Test für Schachcomputer:
https://www.schach-computer.info/wiki/index.php?title=Bratko-Kopec_Test
Da waren anfänglich die Resultate auch i.O. aber mit jedem Jahr, das die Dinger stärker wurden, geriet der Bratko immer mehr in Schieflage, bis er mit den realen Stärkeverhältnissen überhaupt rein gra nichts mehr zutun hatte! Mittlerweile ist er trivial (wenn überhaupt alle seine Puzzles überhaupt korrekt sind…)
Aber zugegeben, euer ERET ist von anderem Kaliber, ich habe ihn kurz nach Erscheinen mit Dutzenden Engines getestet, und dann ein Jahr später mit geupdateten Engines, und das entstandene Ranking war praktisch unverändert. Irgend etwas macht der ERET anders als alle anderen Stellungstests, Kompliment! Wenn ich eine neue Engine downloade, hat sie bei mir immer erst euren ERET zu absolvieren, dann weiss ich ungefähr, wie sie im Vergleich mit Vorgängern oder anderen Engines abschneidet. Keep on the good job! 🙂
Thx, Tim Becker (aus dem hyper hotten München)